如果您无法下载资料,请参考说明:
1、部分资料下载需要金币,请确保您的账户上有足够的金币
2、已购买过的文档,再次下载不重复扣费
3、资料包下载后请先用软件解压,在使用对应软件打开
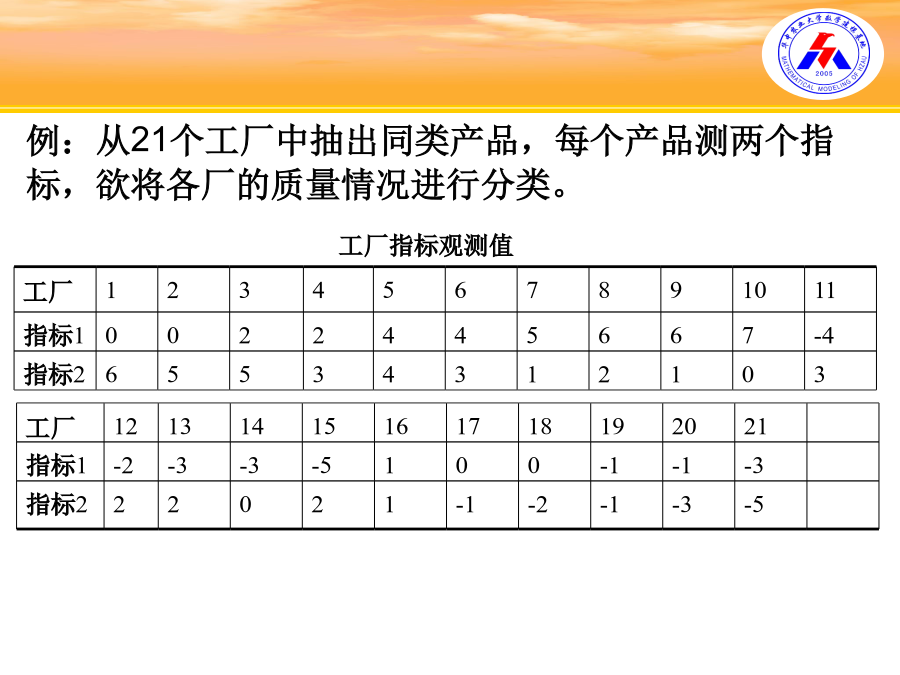
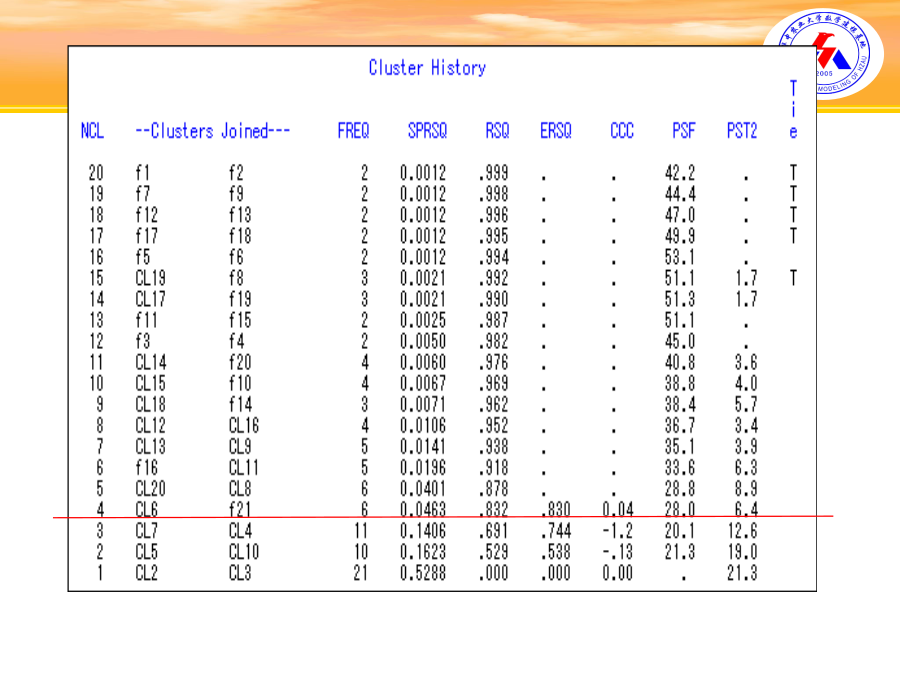
聚类分析又称群分析,它是研究分类问题的一种多元统计方法。所谓类,通俗地说,就是指相似元素的集合。那么要将相似元素聚为一类,通常选取元素的许多共同指标,然后通过分析元素的指标值来分辨元素间的差距,从而达到分类的目的。聚类分析前的预处理步骤:1)确定聚类类型:对样品聚类称Q型聚类;对变量聚类称R型聚类。3)研究样品之间的关系。通常有两种方法:聚类分析的一般步骤(Q-型分类)例:从21个工厂中抽出同类产品,每个产品测两个指标,欲将各厂的质量情况进行分类。dataex;inputx1x2factory$@@;/*$:表示字符型变量*/cards;/*数据省略*/;proccluster/*系统聚类*/data=exmethod=wardcccpseudoouttree=tree;idfactory;run;proctreedata=treehorizontal;/*水平树*/idfactory;/*工厂为样本*/run;ccc表示要计算半偏R2,R2和ccc立方聚类标准统计量,这三个统计量和下面的伪F和伪t2统计量,主要用于检验聚类的效果。当把数据从G+1类合并为G类时,半偏R2统计量说明了本次合并信息的损失程度,统计量大表明损失程度大。R2统计量反映类内离差平方和的大小,统计量大表明类内离差平方和小。ccc统计量的值大说明聚类的效果好。ClusterHistory表示聚类的具体过程,NCL表示当前系统存在类的总个数,ClustersJoined表示当前加入的编号,例如NCL等于20时,是类1,2聚为一类,FREQ表示新类的元素个数。SPRSQ表示类与类间最短规格化最短距离,RSQ表示R2统计量,ERSQ表示半偏R2统计量,CCC统计量值。PSF为伪F统计量,PST2为伪t2统计量。Tie表示“节”,是指当前类间最小距离不止一个的时候,此时可以任意选择一对最短距离进行聚类,在计算其他类与新类的距离。从CCC统计量的结果可以看出,最大值对应的类数为4。从四类合并为三类时,伪t2统计量显著的增加,伪F统计量下降显著,综合各方面的结果,因此分4类最为合适。动态聚类图综合以上分析,可以得到结果,将工厂分为4类,分别为第1类:f1,f2,f3,f4,f5,f6;第2类:f7,f8,f9,f10第3类:f11,f12,f13,f14,f15;第4类:f16,f17,f18,f19,f20,f21。肝病的判别常用的方法有:距离判别法、Fisher判别法、贝叶斯判别法、逐步判别法。这里仅介绍后两种。Bayes判别法的基本思想:总是假设对所研究的对象已有一定的认识,计算新给样品属于各总体的条件概率比较这个概率的大小,然后将新样品判归为来自概率最大的总体。设有总体,具有概率密度函数。并且根据以往的统计分析,知道出现的概率为。即当样本发生时,求他属于某类的概率。由贝叶斯公式计算后验概率,有:Bayes判别法的一般步骤:例题:人文发展指数是联合国开发计划署于1990年5月发表的一份<<人类发展报告>>中公布的数据如下,试通过已知的样品建立判别函数,误判率是多少?并判断待判的归类.类别国家寿命(X1)成人识字率%(X2)调整后GDP(X3)1美国769953741日本79.59953591瑞士789953721阿根廷72.195.952421阿联酋73.877.75370保加利亚71.29342502古巴75.394.934122巴拉圭7091.233902格鲁吉亚72.8992300南非62.980.63799待判样品:中国68.579.31950罗马丽亚69.996.92840希腊77.693.85233哥伦比亚69.390.35159dataex;inputgx1-x3@@;cards;176995374179.5995359178995372172.195.95242173.877.75370271.2934250275.394.9341227091.23390272.8992300262.980.63799;dataex1;inputx1-x3@@;cards;68.579.3195069.996.9284077.693.8523369.390.35159;procdiscrimdata=extestdata=ex1anovamanovasimplelisttestout=ex2;classg;procprintdata=ex2;run;ProcDiscrim后的常用选择项有:(1)Data=数据集名,指定输入数据集名,若缺省则指定最新建立的数据集。(2)Testdata=数据集名,指定待作出判别的数据集名,其中的变量名须